Lessons learnt
Resilience Framework
A continuous thread running through the ResumeNet project has been the development of a framework for resilient networking. The framework reflects what the project has learned about how to design and implement network and service resilience, and as such takes input from all the technical work packages. What has emerged is a systematic approach to network and service resilience, whose core component is a resilience control loop - depicted in Figure 1 - the central element of our resilience framework. To collectively maintain the resilience of networks and services, it is envisaged numerous instances of the control loop operate at multiple protocol levels, across administrative domains, and on different planes.
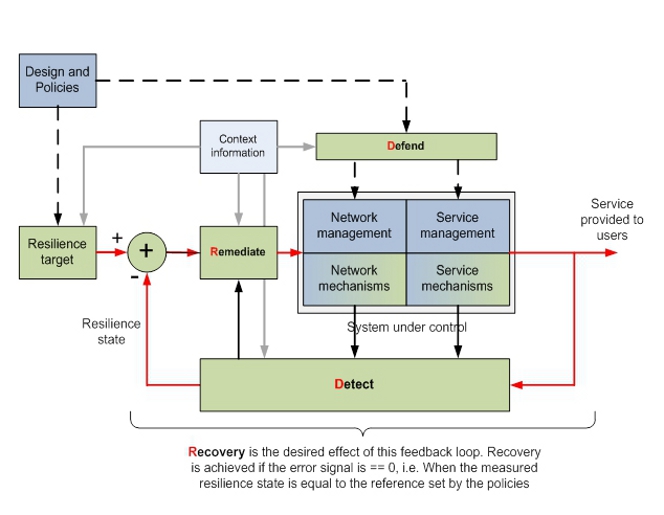
On a high level of abstraction, the system under control is composed of network mechanisms and service mechanisms, which implement the desired properties of the overall system. Examples for such network mechanisms are routing or congestion control mechanisms, needed for resilient forwarding of packets in the network, while examples for service resilience mechanisms depend on the kind of service provided to the user, such as live video or web access. Management components for network and service management allow for the configuration and parametrization of the properties offered by the mechanisms. The system under control is initially built to exhibit a sufficient resilience against challenges; this is the result of the Defend measures, which are defined during the design of the overall system, and guided by operational policies. The design and the operational policies also determine the resilience target, i.e. the reference, which should be maintained by the system under control despite incurring challenges. The service provided to the user is monitored by a Detect component, which draws on information about the way the service is provided as well as about the internal system state. The Detect component computes the resilience state (measured in one of the metrics developed in the project), which is compared with the desired resilience target. If there is a deviation between the target and the actual resilience state, the Remediate component identifies suitable actions that will help to move the system under control towards the desired state, such that it can continue with serving the user in a proper way. Once the system is back to an acceptable operational status, the Recovery phase has been completed; in this model, recovery is seen as the result of a successful operation of the control loop.
It may turn out that - due to unexpected challenges - this control loop does not achieve its goal to restore the proper operation of the system under control. In this case, a second, non-real-time outer control loop (not shown in Figure 1) will be activated for Diagnosis and Refinement. This outer loop cannot operate in real time because its operation implies a re-design of the system under control, taking into account knowledge about novel challenges that were not considered in the original design.
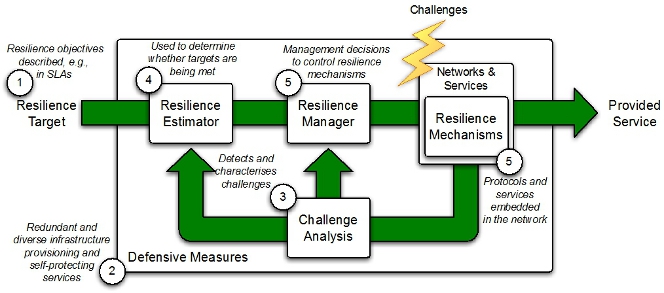
Despite the apparent simplicity of this model, an actual transfer of the model to a concrete implementation proved to be a challenging task, since the system under control is a large distributed and multi-level system, consisting of a multitude of network elements and thousands of services. It goes by itself that the ResumeNet project had to carefully select the instances (or application scenarios) for which the validity of this framework could and should be demonstrated. Towards this goal, an implementation-oriented view of the control loop model, with concrete functional components, was developed and implemented for the selected application scenarios (shown in Figure 2).
To briefly summarise the components of the control loop, initially a resilience target is defined using various multilevel metrics - the purpose of the remaining components is to steer the network toward meeting this target in light of challenges. Collectively, challenge analysis components and a resilience estimator inform a resilience manager about the nature of on-going challenges and the state of the network and services, respectively. Based on this information the resilience manager invokes resilience mechanisms that are embedded in the network and services. Underpinning the operation of the control loop is a set of defensive measures that aim to resist the effect of challenges - these can be passive, e.g., redundant equipment, or active, e.g., firewalls. In some cases, these will prove insufficient, and dynamic adaptation using the control loop will be necessary.
We propose our framework as a consistent approach that identifies how multilevel resilience mechanisms should be deployed. This is based on an understanding of resilience metrics and probable high impact challenges. Resilience mechanisms are managed using a loosely coupled policy-driven management architecture. Our framework improves on the state of the art through this coherent approach. Our resilience framework, which includes implementation guidelines, processes, and toolsets that can be used to underpin the design of resilient networks and services with resilience mechanisms that function at various protocol levels. The elements of our framework that form the key contribution of our research, include:
A multilevel resilience metrics framework
Being able to specify and measure desired levels of resilience is of critical importance, and is understood to be an area in which there is little consensus on how to approach it. Understanding the importance of this problem, a survey was conducted by the European Network and Information Security Agency (ENISA) about the challenges and recommendations for resilience metrics [Eur10]. A set of challenges was identified, including a lack of standard practices, and knowledge and awareness of resilience metrics. In particular, one of the key challenges identified in the survey was: "The lack of a standardised framework, even for the most basic resilience measurements. There are not that many frameworks available and none of them are globally accepted" [Eur10]. Correspondingly, recommendations included stimulating investment, facilitating and encouraging sharing of information and good practices, and the "...development of automated tools to help the deployment of resilience measurement (mainly data collection and data analysis)" [Eur10].
Activities conducted as part of the ResumeNet project to develop the resilience framework are targeted at addressing these two key challenges and recommendations, i.e., a lack of standardised framework and automated toolsets for resilience metrics. We have developed a multilevel resilience metrics framework that can be used to understand and describe the resilience of networks and services, and the relationship metrics from different levels of the protocol stack have, e.g., whether they exhibit correlated or orthogonal behaviour. Accompanying the framework is a set of tools, such as simulation models and software libraries for examining metrics, that can be used to evaluate a given network topology in the presence of various challenges.
Processes for understanding challenges
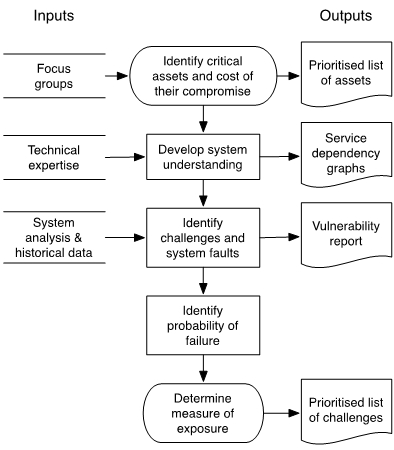
Deployed resilience mechanisms should be targeted at addressing the most probable high-impact challenges the network may face. In the context of network resilience, the challenges that could occur transcend those normally considered in other thematic areas, such as information security, fault tolerance and disruption tolerant networks. Without considering this broad spectrum of challenges, mechanisms could be inappropriately deployed. To manage this problem, we have developed a risk assessment process, depicted in Figure 3, which can be used to identify high-impact challenges. This process builds on an informal categorisation of the forms of challenges that one must consider to ensure network resilience.
A resilience management architecture
The management of multilevel resilience mechanisms that potentially interact across different administrative domains can be complicated. Furthermore, the operation of resilience mechanisms should in many cases be done in real-time with potentially limited human intervention; incorrect operation could have significant negative consequences. To tackle these issues, we have developed a loosely coupled network management architecture, which makes use of policies to specify multi-stage resilience strategies - configurations of mechanisms that address a given challenge set. By using policies, strategies can be carefully crafted and evaluated, using a policy-driven network simulator we have developed, without the need to take resilience mechanisms off-line.
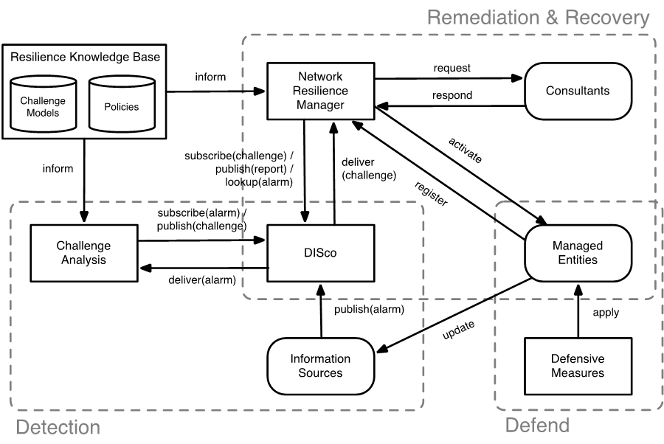
To validate the management architecture, we have applied it in a security context using Or-BAC policy-based management formalism. In short, the architecture proposes two main modules, which are the Policy Instantiation Engine (PIE) and the Policy Decision Point (PDP), which collectively implement the network resilience manager functionality. The PIE implements an Or-BAC access policy, and dynamically adapts this policy according to the information retrieved from Intrusion Detection Message Exchange Format (IDMEF) alert messages [DCF07]. These messages originate from the Distributed Store for Challenges and their Outcome (DISco). The PDP retrieves the newly triggered policy rules and explores techniques to deploy the new policy, based on the capabilities of the Policy Enforcement Points, i.e., managed entities embedded in the network, such as firewalls and servers.
A set of novel resilience mechanisms
We have developed a number of resilience mechanisms that can be applied to a wide range of challenges. They span a number of stages of the D²R²+DR strategy and function at the network and service level. In particular, we have produced mechanisms to address malicious behaviour in networks, such as monetary-less cooperation incentives to mitigate selfish nodes in wireless mesh networks, game-theoretic approaches to protection against malware propagation, and an anomaly detection approach to detect and traceback attacks on encrypted protocols. Furthermore, our mechanisms can be applied at different levels of the protocol stack in light of node and link failure, and include novel approaches to multi-path routing in multi-hop wireless networks and algorithms for creating resilient large-scale overlay networks.
An enemy of network resilience is complexity; using multilevel resilience mechanisms that share information and perform cross-layer control has the potential to increase complexity and produce undesirable emergent behaviours. To address this problem, we have developed a cross-layer framework, which uses a formalism to evaluate the optimal layer to place resilience functionality, thus reducing replicated functionality at different layers.
Approaches to challenge detection
Our understanding of the purpose of the detect stage of the D²R² + DR strategy has evolved over the lifetime of the project. We understand that its primary goal is to build situational awareness to inform decision-making regarding remediation and recovery. To identify challenges, we propose an incremental multi-stage approach that enables rapid remediation to reduce the likelihood of challenges causing catastrophic failure. Subsequently, remediation can be refined using improved identification mechanisms. To support this multi-stage approach, we have developed an architecture, which can be implemented using model-driven fault localisation techniques.
Ensuring resilience is a venture that should be tackled at multiple levels of the protocol stack in diverse topological (and geographical) locations. This involves information sharing across protocol layers, to build situational perception. We have investigated what multilevel metrics should be measured for resilience, and which tools should be used to collect and distribute this information.
Aspects of the framework are readily applicable, whereas other elements represent our longer-term vision of how to realise network resilience. For example, the toolsets that are part of the multilevel metrics framework can be applied immediately to gain an understanding of the resilience of networks and services to various challenges. Furthermore, some of the resilience mechanisms we have developed, particularly those that operate at the service level, can be used to address challenges in the near-term future. Our longer-term vision for ensuring network resilience is embedded in our resilience management architecture and challenge detection approaches. These are arguably more disruptive from a (business) processes and technical implementation perspective, and further research is required in some cases to confirm their applicability.
Experimentation
One of the major goals of the experimentation activities proposed in ResumeNet has been to determine the extent to which the D²R² + DR resilience strategy can be applied in practical network settings. One of the major conclusions is that there are certain scenarios where most of the functionality is provided by only one component of the strategy, whereas in other scenarios two related components have the same function and therefore operate as one logical block.
The former is highlighted by the experimentation scenario that considers selfishness in multihop wireless mesh networks (see ResumeNet deliverable D4.2b for further details of this scenario). Nodes try to discover the network topology and traffic matrix, where due to the distributed nature of the system, no systematic misrepresenting can be done by flows. Here the emphasis is on individual nodes, which based on the data gathered from the network construct their own flow dependency graph. The graph is then used to identify nodes to which the local host should not offer forwarding, since reciprocation could not be achieved. There is obviously a game where each player is a flow and the strategy played is the route to be used. Such a one-shot game does not have a separate phase to deal with free-riding (this would represent recovery and remediation). Therefore, this functionality has to be built into the strategy selection component, which is by definition the defence phase. In fact, defence is self-enforcing in this scenario, in the sense that hosts that find each other collaborating as a result of the dependency graph calculation would not like to change their strategy. The second scenario, which considers the resilience of opportunistic networks, provides an interesting insight into the D²R² + DR resilience strategy as well. Since these networks are an extremely distributed environment, detection is extremely hard to achieve, being limited essentially to a few special cases. One of the consequences is that the separation between challenged and unchallenged networks is not clear, since even the normal mode can be considered as challenged. It is for this reason that recovery and remediation form the same functional block.
The application of D²R² + DR strategy to multi-level resilience has proved to be complex from an experimental point of view. Most of the multi-level applications are in the wireless area, where the interactions between the PHY, MAC and network layer can produce unexpected results, due to the fact that these protocols were developed independent of each other. Theoretically, in order to provide optimality (or resilience) for the network, a set of coupled optimizations has to be solved, which is usually intractable. However, our experiments deal with a number of multi-level aspects. The incentive protocol for wireless mesh networks uses application layer information gathered at the network layer, the CRS system can process information collected at multiple levels, and the migration in virtualized environments has been evaluated on different levels.
Other results
In addition to the scientific foreground developed on the ResumeNet project, a set of resilience teaching material was developed. In collaboration with the Euro-NF Network of Excellence, ResumeNet organized a network resilience PhD Course on September 26-28, 2011 at ETH Zürich (Switzerland). The three-day event covered widespread network resilience aspects, including exercises. As a result, ResumeNet produced a set of slides, which can be used by others to integrate network resilience into their courses. The series of eight lectures and exercises, compiled by international teachers, surveyed fundamental and applied aspects of network resilience, and identified novel opportunities and research directions in this area. The intended audience for the teaching material is graduate students - Masters and PhD students. Specifically, the topics covered in the teaching material are:
·Resilience principles and related disciplines;
·Resilience metrics;
·Modeling the network operation under challenges and assessing its resilience;
·Resilient routing;
·Detecting and Preventing Malicious Network Activities;
·Challenges in the current Internet & Building Resilient Services; and;
·Virtualization and resilience.
The lecture slides produced are accompanied with a practical exercise that students can attempt, which tasks them with developing resilience functionality using programmable switching technology.
©Copyright by ResumeNet
!!! This document is stored in the ETH Web archive and is no longer maintained !!!